The Hidden Complexity of Document Splitting

By Riley Matthews, Applied AI, Stream Claims
The segmentation problem
We work on end-to-end automated claims analysis for workers' compensation and bodily injury carriers, defense firms, and state agencies. Every case arrives as a large packet of documents, and often that packet consists of a few extremely long PDFs, each of which is the concatenation of many documents. A single packet typically runs from a few hundred to tens of thousands of pages.
Packets contain medical records from multiple providers, demand letters, bills, depositions, employer reports, rehab notes, prescription records, to name a few. Internally we use various taxonomies to model the high-volume document families in that stream, while still handling the edge cases that real packets produce: ad hoc handwritten notes, receipts, floating images of damaged vehicles or other indeterminate scenes without attached textual description, and the inevitable one-offs we have not yet encountered.

For the complex, many-thousand-page cases that make up the bulk of our work, the packet has to be decomposed into its coherent component documents before any of that material can be effectively analyzed and reasoned about at scale. That task is document segmentation (alternatively known as page stream segmentation, or document splitting).
Why it's difficult
Splitting a 40k-page, omnibus PDF into its constituent documents is hard, and holding high-90s F1 gets harder the deeper into the long tail of real packets you go. A few of the recurring difficulty factors:
- Visually identical templates that require semantic understanding to tell apart. An EMR template gets reused across forty dates of service. A rehab note’s content is copy-pasted across weekly sessions, with only the date updated. A provider letterhead and form layout repeat page after page. Two adjacent pages can look continuous yet describe distinct encounters; the boundary lives in semantic space: a new date of service, a different clinical event, or another distinction visible only to a reader parsing the textual content.
- Attachments and sub-documents. Packets are full of attachment patterns that do not cooperate. A clinician handwrites "see attached" without any other structural indication of the connection. A form interrupts its own flow with supplementary paperwork. Some inserted material is not really a document at all: photos, IDs, cropped clinical images. Depending on context, that material may need to be separated from adjacent pages or absorbed into the surrounding segment.
- Out-of-order, duplicated, and degraded pages. Packet assembly does not guarantee logical order. Pages can arrive reversed, missing, duplicated, or scattered hundreds of pages apart. A result from June can sit between March notes. A cover letter introducing an attached document can appear at the end of that document. On top of this, handwriting, poor scans, and fax artifacts add a layer of information loss that makes correct interpretation harder.

Generic segmentation solutions hit a ceiling in complex domains
Generic document-segmentation tools, i.e., the kind trained and marketed in isolation from any particular downstream task, run into a hard performance ceiling when applied to claims work. And that ceiling is not a compute problem that could be solved by scaling intelligence of the underlying models. It’s a specification problem:
- First, "correct" segmentation is only well-defined in the context of the larger system's goals. A claim packet doesn't have a platonic decomposition in the abstract. Whether two adjacent spans should be split or grouped depends on what the integrated system is going to do with them. The same packet has different correct cuts under different goals. A generic splitter is specified against whatever granularity its annotators happened to agree on, and that granularity is useful for some goals and wrong for others. You can make it more performant against generic benchmarks, but you cannot resolve the ambiguity of the segmentation task in isolation, without reference to the wider system's goals.
- Second, pushing towards performance in the high-90s requires handling long-tail, domain-specific document scenarios. The head of the distribution is where generic segmentation solutions land where their benchmarks say they should, somewhere in the 70-80% boundary F1 range. Moving from there to production-grade output for claims work requires mastery of the tail: unusual record structures, idiosyncratic packet assembly habits, and domain-specific knowledge about what does and does not need to be analyzed together. The jump to production-grade performance in a complex domain comes from continually accumulating and encoding that long-tail domain knowledge into the splitter itself.
Our performance
For page-level segmentation (stay tuned for a later post on line-level segmentation), we frame and measure performance as a page-boundary problem evaluated against real completed cases, with the reference labels reviewed and corrected by domain specialists. What we're measuring, in other words, is how closely our system's output matches what the people actually doing end-to-end claims analysis treat as correct.
Cohort. 682 completed cases across four workers' comp and bodily injury carriers, all ≥ 200 pages, over the last 60 days (snapshotted on April 23rd, 2026). Total 524,682 pages.
Snapshot. We compare what the system outputs at the end of automated processing — before any human has touched it — against the final state of the case as independently adjudicated and submitted by a domain specialist.
A single summary statistic will not fully capture the "goodness" of a segmentation. In practice we use (a) a suite of measures, e.g., page-boundary F1 alongside boundary similarity and perfect-case rate, that give different angles on performance and (b) more qualitatively, various visualizations of predicted vs. reference cuts that can give a richer impression of the “shape” of a segmentation’s errors/misalignment. Different failure modes carry different costs depending on what the integrated system is trying to accomplish, and no single metric characterizes all of those costs.
For simplicity, however, in this performance evaluation we will just use a couple of F1 variants.
- F1 All. F1 when every predicted break and every real break counted in the metric.
- F1 Consequential Pages. F1 when we exclude predicted and actual breaks that are strictly within spans of reviewer-discarded pages. That is, we don’t give or deduct credit for predictions within page ranges where exact placement would not have affected downstream claim analysis. The system (and reviewer) chose to exclude and ignore spans of pages as unrelated or inconsequential to the analysis.
There's also a choice about how to aggregate the F1 metric across cases. Per-case median answers "what does a typical case look like?" Page-weighted aggregate answers "what happens when the largest, ugliest packets get their full share of attention?" The second is intentionally harsher. A lot of the operational pain in claims analysis lives in the fat tail of behemoth cases, and we want a metric that tracks these cases heavily.
The gap between 95.7% per-case and 88.8% page-weighted tells a real story: larger cases are harder and have higher variance, and the per-case median hides that.
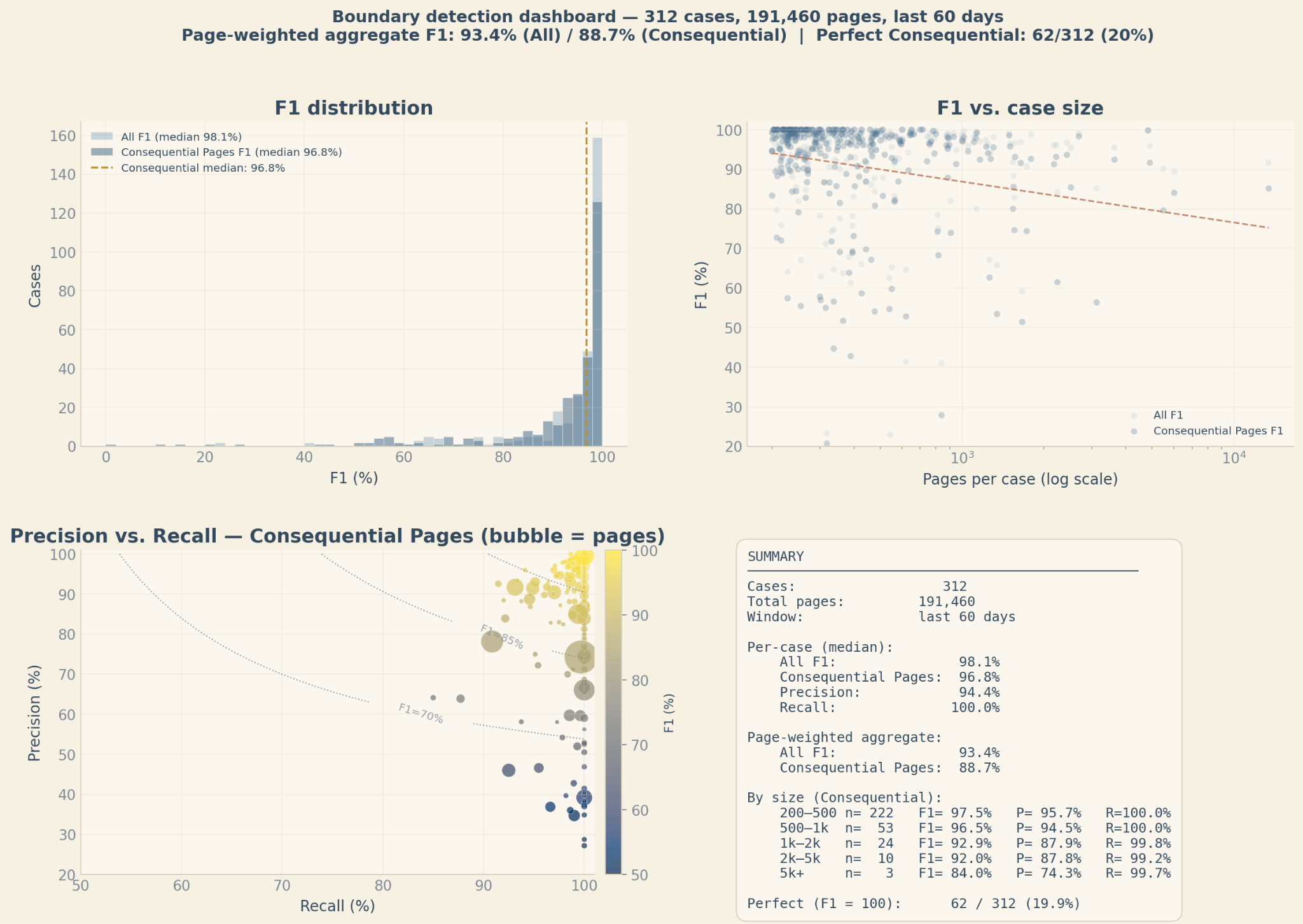
Performance holds 91–95% on the main metric across the 500–5,000-page band, which is where the bulk of the operationally painful cases live.
Reference Baselines
To put these numbers in context, compare them against systems that are closer to generic document splitting than to claims-specific segmentation.
- As a baseline closer to our own data, we trained a Google Cloud Document AI custom splitter on an easier subset of our claims documents, using the maximum training set size the tool allowed. Evaluated under the same “All” page-weighted boundary-F1 framing, it reached 57% F1, which serves as a useful reference point for what a relatively generic custom splitter can do when it has limited room to adapt to the domain.
- A generic document-processing vendor reports roughly 70–80% F1 on the PoliTax Split dataset, a hand-labeled benchmark it released from public-domain tax documents. That dataset is not claims data, but it does resemble a small slice of the distribution we encounter. The comparison is imperfect but directionally useful: getting from “credible generic splitter” to production-grade claims segmentation is the hard part.
These reference points show that general-purpose splitting can be useful, but also that production-grade claims segmentation is a different regime. The hard part is adapting to the long-tail packet structures and downstream claims-analysis goals that define what the right break is.
Segmentation Is an Integrated System Component
This is the larger point. Segmentation, like each subtask in a claims-analysis system, is ultimately in service of the integrated system’s goals. Off-the-shelf generic tools, blind to those aims, are necessarily performance-capped. The ceiling is not about the model or the raw intelligence deployed; it is about the specification (explicit or implicit) the model is fit to, and the gap between that specification and the actual aims of the integrated system.
A segmenter whose specifications we iteratively refine and align to what the larger system is trying to accomplish becomes part of a feedback loop, one where the upstream component, the experts who define correctness, and the downstream intelligence doing the analysis are all optimizing the same thing: reliable, underwriteable claims decisions and rationale.
